Multi Agent RL & Web3
Update at 2025.02.08: I write an implement of this idea https://github.com/haoruilee/Principal-Agent-Contract
Recently I read this paper Principal-Agent Reinforcement Learning: Orchestrating AI Agents with Contracts https://arxiv.org/pdf/2407.18074 and find it interesting. Not only cuz it trying to solve MARL (Multi-Agent Reinforcement Learning) but also cuz it may comes another point that Agent and Web3 come togther.
Based on this paper’s algo, I proposed this Semi-on-Chain solution struct to solve SSDs (Sequential Social Dilemmas). I havent write the code yet but I may apply it to some Hackathon. If you are interested in this idea, contact me and we can build together!
Introduction: Tackling Multi-Agent Chaos
Have you ever had a group project where everyone wanted to get a good grade, but half the team was slacking? Or seen traffic turn into a jam because no one wanted to let others pass? In these situations, individual incentives (like “I don’t want to do extra work” or “I want to be first!”) can clash with the greater good.
This tension is typical of multi-agent systems. Each agent (or participant) acts for itself, yet there’s a bigger system we care about—like a road network, a shared environment, or even an online collaborative platform.
In multi-agent reinforcement learning (MARL), we try to teach agents how to behave well in a shared environment. But that alone might not guarantee cooperation, especially if agents are purely self-interested. This is where economics-inspired “contracts” and trustless blockchain execution (Web3) come in.
Section 1: Structure Overview
Let’s start with a simple Structure diagram that shows all the pieces—MARL (our learning approach), Q-learning (the algorithm within MARL), Contracts (from economics, for incentives), and Web3 (blockchain-based execution).
1 | +--------------------------------------------------+ |
- Off-chain RL: We do the heavy-lifting of training the agents and optimizing the contract offline or in a simulator.
- Smart Contract: Lives on a blockchain, enforces the final incentive rules automatically (no cheating!).
- Multi-Agent Environment: Where the actual interactions happen—like a traffic system, a fishery resource, or a game board.
Section 2: Background
2.1 Multi-Agent Reinforcement Learning (MARL)
-
What is MARL?
Think of a group of robots in a factory needing to coordinate. Each robot is an agent. They share the workspace but have local goals (like finishing tasks quickly). MARL helps them learn collectively without a single “boss” controlling them. -
Why is it tricky?
Agents aren’t just reacting to a static environment. They’re reacting to each other. One robot’s path might block another’s route.
2.2 Q-learning Basics
-
Definition:
Q-learning is a type of reinforcement learning that estimates a “Q-value,” which tells you how good it is to take action in state , considering future rewards. -
Simple example:
Imagine you’re learning to park your car. State might be your position and orientation, action is turning the wheel left or right, and the reward is how close you get to a perfect park. Over many attempts, you refine your Q-values until you get the hang of it.
2.3 Principal-Agent Contracts
-
What is a contract in this context?
Suppose your boss can’t see how hard you work; they only observe results—like project success. A contract might say: “If the project meets quality X, you get Y bonus.” It incentivizes you to aim for X, even if the effort is hidden. -
Why do we need it here?
In a multi-agent system, an agent might do actions you can’t monitor directly. So you pay (or punish) them based on an observable outcome instead.
2.4 Web3 (Blockchain + Smart Contracts)
-
Blockchain:
A shared ledger that no single entity fully controls. Like a big spreadsheet, but each row is verified by many people (nodes). -
Smart Contracts:
Small pieces of code that automatically run on the blockchain.
Example: If you have a distributed ridesharing app, you can store “If passenger confirms arrival, automatically pay the driver 10 tokens” in a smart contract. There’s no single company controlling the transaction—it’s automatically executed once the condition (passenger confirmation) is met.
Section 3: How They All Fit Together
The big magic here is that agents learn (via Q-learning) in an environment, while a principal designs a contract to shape their behavior. Finally, Web3 ensures the agreed-upon payments are actually honored in a trustless manner.
-
Agent’s Perspective:
“I want to maximize my total reward, which includes environment rewards (like finishing tasks) and any bonus from the contract. So I’ll do Q-learning to figure out which actions yield me the best payoff.” -
Principal’s Perspective:
“I can’t force your hidden actions, but I can pay you if you produce outcomes that help the overall system. Let me figure out the minimal payment that still nudges you to do the right thing.” -
Blockchain Smart Contract:
“Just give me the rule for how to pay or not pay. When I get verifiable data from an oracle about the outcome, I’ll auto-execute the transaction, so no one can renege.”
Section 4: More Everyday Examples
-
Traffic Coordination Example
- Agents = self-driving cars.
- Principal = city’s traffic authority that wants fewer jams.
- Contract = “If you yield at intersections to keep traffic flowing, you get micro-payments.”
- Web3 = A traffic DAO on a blockchain, so every car’s signals (like yield events) get logged, and the smart contract pays them instantly if the yield event was beneficial.
-
Fisheries Management Example
- Agents = fishing boats.
- Principal = a fishery conservation board.
- Contract = “If you stay within a sustainable catch quota (verified by a satellite or port weigh-in), we pay you a bonus.”
- Web3 = The contract is on a public chain, ensuring no fishery officer can do under-the-table deals or that no boat can claim “we didn’t catch that many fish!” if the satellite/oracle data disagrees.
-
Online Marketplace Example
- Agents = sellers on a platform.
- Principal = platform operator wanting high-quality listings.
- Contract = “If your product rating stays above 4.5 with at least 100 reviews, you get a monthly bonus from the platform.”
- Web3 = The bonus is coded into a smart contract, so you can’t manipulate or skip paying. If oracles confirm your rating is 4.5+, the payout is automatic.
Section 5: Under the Hood (Some Math)
In the paper Principal-Agent Reinforcement Learning: Orchestrating AI Agents with Contracts https://arxiv.org/pdf/2407.18074 you can get clear conductions.
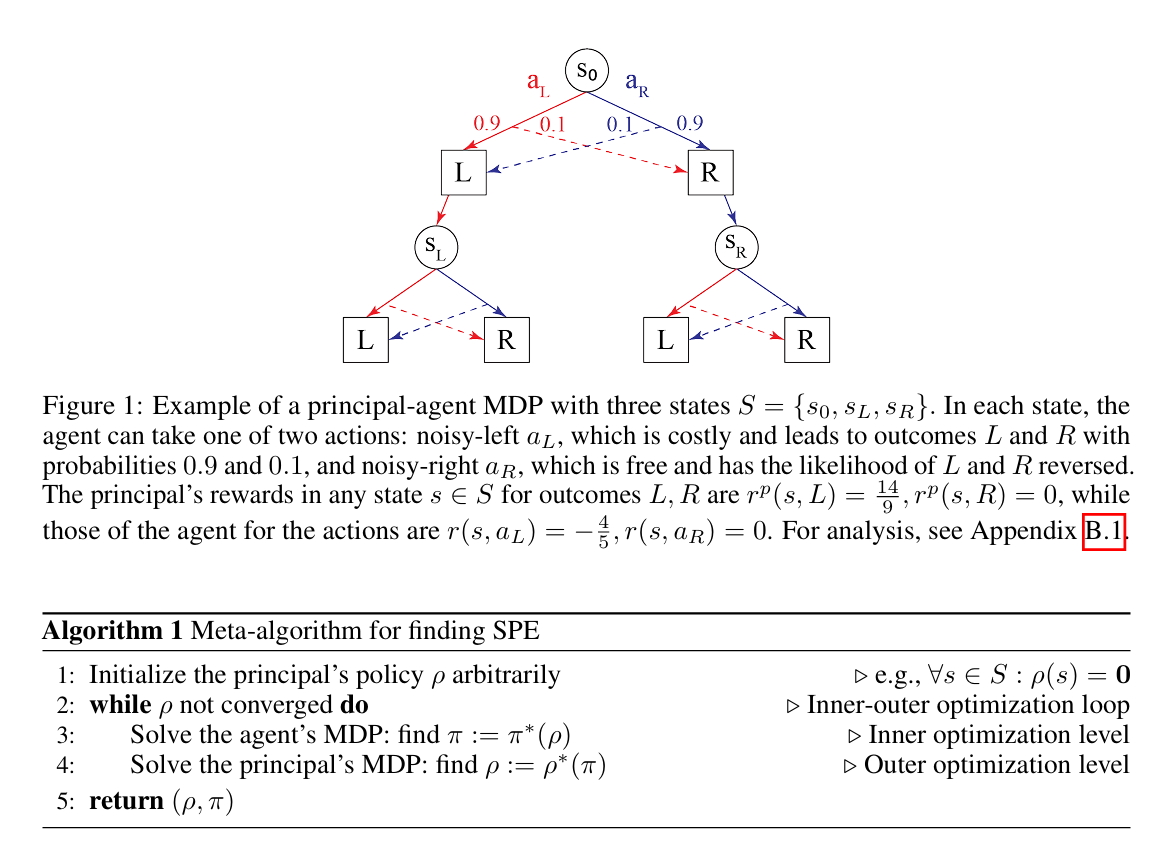
Let’s get just a little technical here in this blog:
5.1 Agent’s Q-function
When the principal chooses a “contract policy” (meaning, how it sets payments in each state), the agent’s Q-value looks like this:
- The agent picks that maximizes both the immediate payment from plus the environment-based cumulative reward.
5.2 Principal’s Optimization
The principal tries to set contract so that the agent’s best action in each state aligns with the principal’s goal. Usually, we write something like:
subject to the constraint that the agent’s best response is the “good” action.
5.3 Convergence
If we keep iterating:
- Agent updates its Q-values to respond to the contract.
- Principal updates the contract once the agent’s new best responses are known.
We can often converge to a stable subgame-perfect equilibrium (SPE) if the horizon is finite or certain conditions hold.
Section 6: Putting It together
-
Off-chain:
We do big computations (like Q-learning, large neural network updates) offline or in a private server. -
On-chain:
We store the final “contract function.” For instance, something that says: “If outcome is , pay agent X tokens.” Payments happen automatically, removing the need for a central admin.
1 | +---------------- Off-chain RL (Principal & Agents) ------------------+ |