Deepseek Math Paper Reading
Main Contribution
- GRPO, bring ‘group’ method to training, remove value model in workflow. “GRPO foregoes the critic model, instead estimating the baseline from group scores, significantly reducing training resources compared to Proximal Policy Optimization (PPO).”
- A unified RL formula for RFT, DPO, PPO, GRPO
- RL training tricks:
- Outcomes supervision RL is better than process superversion RL
- Iteration RL, train reward model every several inter to make it updated
From PPO to GRPO


Proximal Policy Optimization (PPO) is an actor-critic RL algorithm widely used in the RL fine-tuning stage for LLMs. PPO optimizes LLMs by maximizing the following surrogate objective:
where:
- $ \pi{\theta} $ and $ \pi{\theta_{\text{old}}} $ are the current and old policy models, respectively.
- $ q $ and $ o $ are quesns and outputs sampled from the question dataset and the old policy $ \pi{\theta{\text{old}}} $.
- $ \epsilon $ is a clipping-related hyper-parameter introduced in PPO for stabilizing training.
- $ At $ is the advantage, computed using Generalized Advantage Estimation (GAE) (Schulman et al., 2015), based on rewards $ {r_t} $ and a learned value function $ V{\psi} $.
In PPO, a value function needs to be trained alongside the policy model. To mitigate over-optimization of the reward model, a per-token KL penalty from a reference model is added to the reward at each token:
where:
- $ r_{\phi} $ is the reward model,
- $ \pi{\theta{\text{ref}}} $ is the reference model (usually the initial SFT model),
- $ \beta $ is the coefficient for the KL penalty.
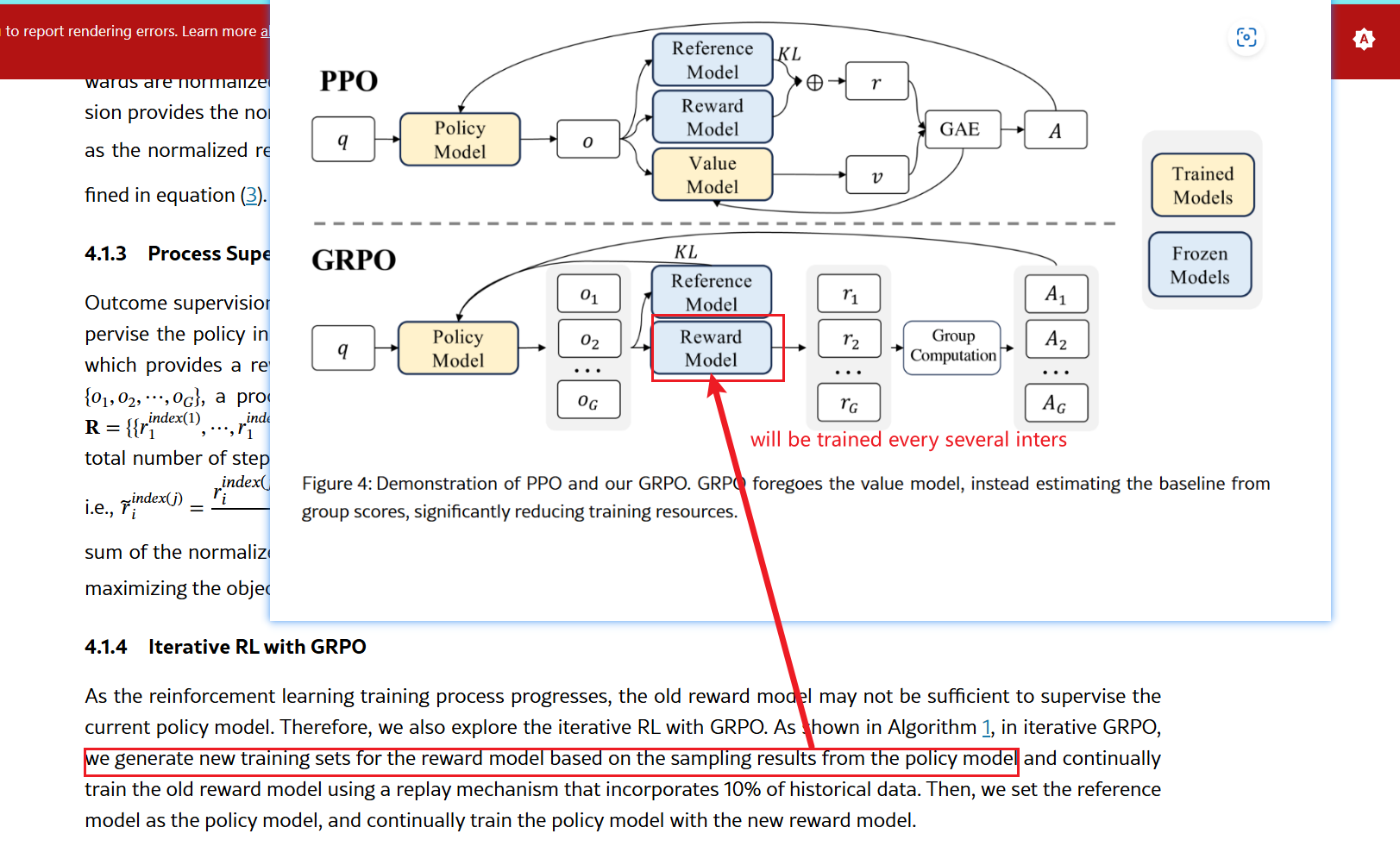
GRPO foregoes the value model, instead estimating the baseline from group scores, which significantly reduces training resources.
PPO requires a large memory and computational burden due to the value model, which is typically of comparable size to the policy model. Moreover, in LLM contexts, usually only the last token is assigned a reward score, complicating the training of an accurate value function at each token.
To address this, Group Relative Policy Optimization (GRPO) eliminates the need for an additional value function, using the average reward of multiple outputs produced in response to the same question as the baseline. Specifically, for each question $ q $, GRPO samples a group of outputs $ {o1, o_2, \dots, o_G} $ from the old policy $ \pi{\theta_{\text{old}}} $ and optimizes the policy by maximizing the following objective:
where:
- $ \hat{A}^i_t $ is the advantage computed based on the relative rewards of outputs inside each group,
- $ \beta $ and $ \epsilon $ are hyper-parameters,
- $ D{\text{KL}}[\pi{\theta} | \pi{\text{ref}}] $ is the KL divergence between the trained policy $ \pi{\theta} $ and the reference policy $ \pi_{\text{ref}} $.
The advantage is computed relative to the group, aligning well with reward models that are typically trained on datasets comparing outputs for the same question.
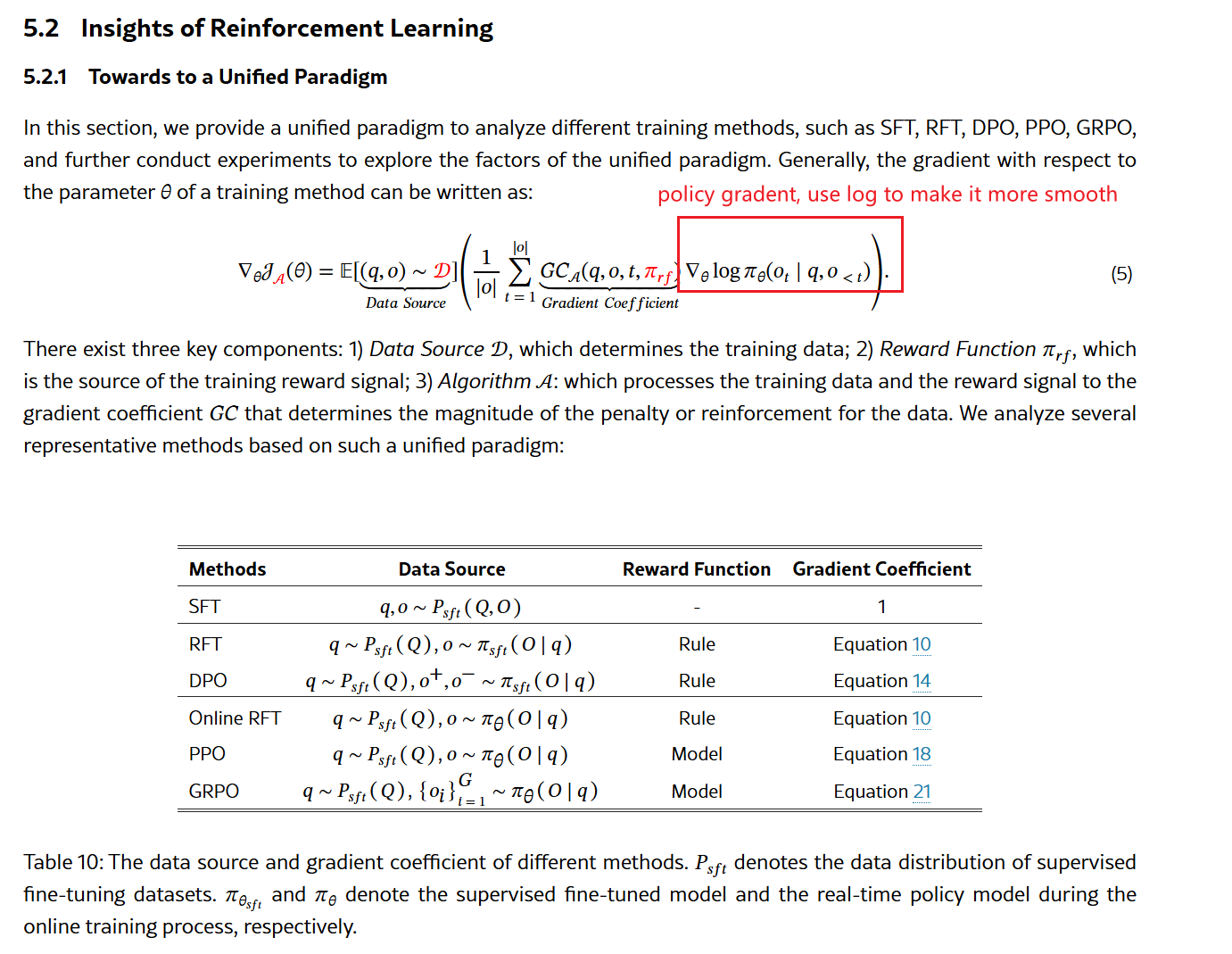
Insights of Reinforcement Learn
DeepseekMath also propose a unified form of RL: