DeepSeek R1 Paper Reading
DSR1 paper https://arxiv.org/pdf/2501.12948
Main Contribution
- Post-Training: RL was directly applied to the base model, resulting in DeepSeek-R1-Zero, which demonstrates capabilities like self-verification and long chain-of-thought (CoT) generation, showing that LLM reasoning can be enhanced purely through RL without supervised fine-tuning (SFT).
- Pipeline for DeepSeek-R1: A pipeline with RL and SFT stages was introduced to improve reasoning and align with human preferences, aiming to create better models for the industry.
- Distillation: Large model reasoning patterns can be distilled into smaller models, which perform better than RL-discovered patterns in smaller models.
Pipeline
As we have read the GRPO algo in previous blog https://lihaorui.com/2025/02/05/deepseek-math-reading/ here we continue read deepseek r1’s training pipeline.
My drawio source: https://drive.google.com/file/d/1ktUdHutP31jZUaRf6fmnAIxeFT_PSuPZ/view?usp=sharing
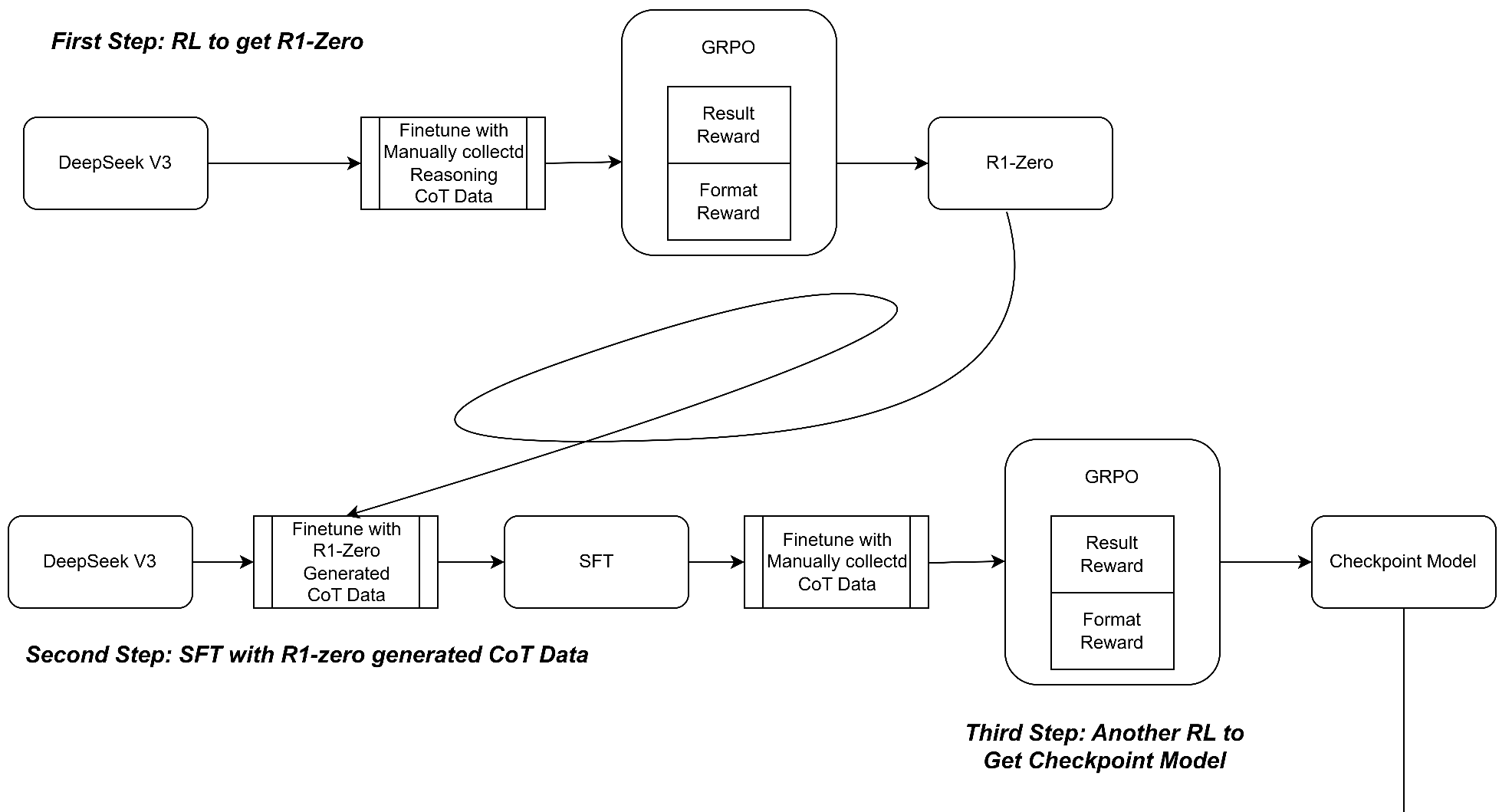
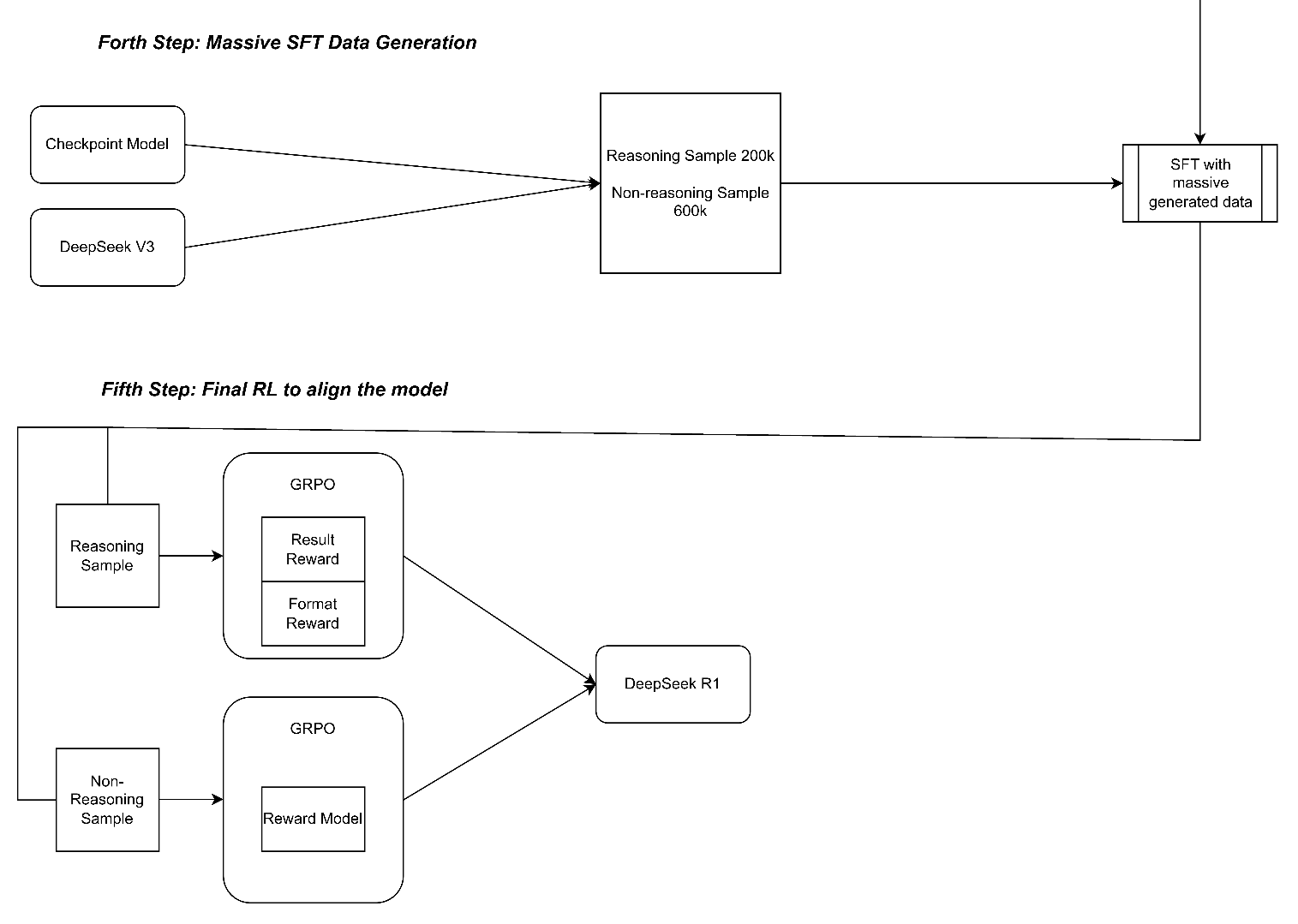
Two key points: 1. GRPO RL can get really good model. 2. Generate reliable SFT data from small size to large size
Step1: RL to get R1-Zero
Step2: SFT with R1-Zero generated CoT Data
Step3: RL to get checkpoint model
Step4: Use checkpoint model and deepseek-v3 to generate massive SFT data then do the SFT
Step5: Final RL to get R1
Insights
This paper also highlight several insight of model trianing:
Special Token to summarize

Get a big one then distrill
First, distilling more powerful models into smaller ones yields excellent results, whereas smaller models relying on the large-scale RL mentioned in this paper require enormous computational power and may not even achieve the performance of distillation. Second, while distillation strategies are both economical and effective, advancing beyond the boundaries of intelligence may still require more powerful base models and larger scale reinforcement learning
Process Reward Model (PRM)
Once a model-based PRM is introduced, it inevitably leads to reward hacking
MonteCarloTreeSearch(MCTS)
Token generation presents an exponentially larger search space, not suited
GRPO code
While reading this paper, I collected some GRPO code, it can be used for efficient fine-tune: https://github.com/haoruilee/Awesome-GRPO-training-example
Espically this one: https://www.kaggle.com/code/danielphalen/grpotrainer-deepseekr1 also provide example dataset
Open R1
Huggingface also opensourced a reproduction of R1, still reading
https://github.com/huggingface/open-r1
More Fun Facts
Cool things from DeepSeek v3’s paper:
- Float8 uses E4M3 for forward & backward - no E5M2
- Every 4th FP8 accumulate adds to master FP32 accum
- Latent Attention stores C cache not KV cache
- No MoE loss balancing - dynamic biases instead
More details:
- FP8: First large open weights model to my knowledge to successfully do FP8 - Llama 3.1 was BF16 then post quantized to FP8.
But method different - instead of E4M3 for forward and E5M2 for backward, used ONLY E4M3 (exponent=4, mantissa=3).
Scaling is also needed to extend the range of values - 1x128 scaling for activations and 128x128 scale tile for weights.
During used per tensor scaling, and other people use per row scaling.
FP8 accumulation errors: DeepSeek paper says accumulating FP8 mults naively loses precision by 2% or more - so every 4th matrix multiply, they add it back into a master FP32 accumulator.
Latent Attention: Super smart idea of forming the K and V matrices via a down and up projection! This means instead of storing K and V in the KV cache, one can store a small slither of C instead!
1 | C = X * D |
During decoding / inference, in normal classic attention, we concatenate a new row of k and v for each new token to K and V, and we only need to do the softmax on the last row.
Also no need to form softmax(QK^T/sqrt(d))V again, since MLP, RMSNorm etc are all row wise, so the next layer’s KV cache is enough.
During inference, the up projection is merged into Wq:
1 | QK^T = X * Wq * (C * Uk)^T |
And so we can pass these 2 matrices to Flash Attention!
- No MoE loss balancing: Instead of adding a loss balancer, DeepSeek instead provides tuneable biases per expert - these biases are added to the routing calculation, and if one expert has too much load, then the bias will be dynamically adjusted on the fly to reduce it’s load.
There is also sequence length loss balancing - this is added to the loss.
- Other cool things:
a) First 3 layers use normal FFN, not MoE (still MLA)
b) Uses DualPipe for 8 GPUs in a node to overlap communication and computation
c) 14.8 trillion tokens - also uses synthetic data generation from DeepSeek’s o1 type model (r1)
d) Uses YaRN for long context (128K). s = 40, alpha = 1, beta = 32 - scaling factor = 0.1*log(s) + 1 ~= 1.368888